This repository includes various attention visualization examples of monotonic multihead attention (MMA) for online streaming end-to-end ASR task.
Paper Title: Enhancing Monotonic Multihead Attention for Streaming ASR
Authors: Hirofumi Inaguma, Masato Mimura, Tatsuya Kawahara (Graduate School of Informatics, Kyoto University, Kyoto, Japan)
Abstract:
We investigate a monotonic multihead attention (MMA) by extending hard monotonic attention to Transformer-based automatic speech recognition (ASR) for online streaming applications.
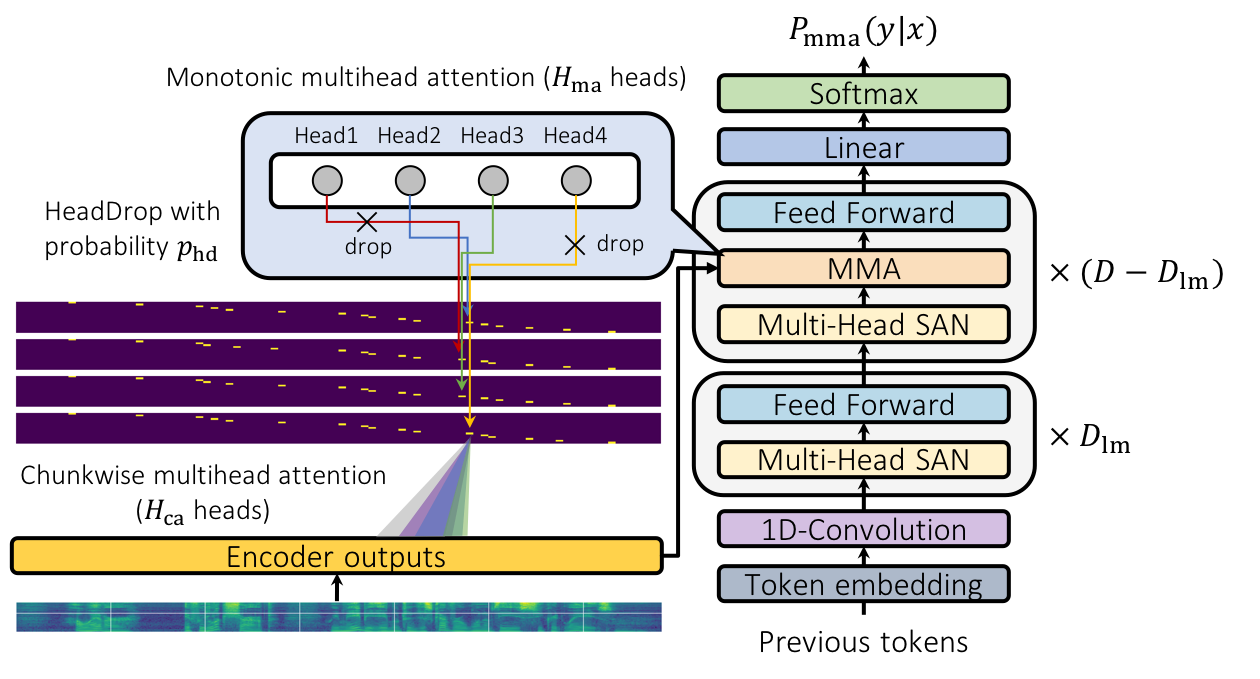
For streaming inference, all monotonic attention (MA) heads should learn proper alignments because the next token is not generated until all heads detect the corresponding token boundaries.
However, we found not all MA heads learn alignments with a naïve implementation.
To encourage every head to learn alignments properly, we propose HeadDrop regularization by masking out a part of heads stochastically during training.
Furthermore, we propose to prune redundant heads to improve consensus among heads for boundary detection and prevent delayed token generation caused by such heads.
Chunkwise attention on each MA head is extended to the multihead counterpart.
Finally, we propose head-synchronous beam search decoding to guarantee stable streaming inference.
System overview
Attention visualization
Upper (lower) yellow dots reprsent detected token boundaries by MA heads in upper (lower) decoder layers.
Left: Utterance ID "116-288045-0000" from dev-other set
Right: Utterance ID "116-288045-0001" from dev-other set
Offline MMA models with standard beam search decoding (Librispeech960h), Table 1
A1. Baseline MMA (naive implementation), D_lm=0, w=4, H_ma=4, H_ca=1
A2. Pruning MA heads in lower decoder layers, D_lm=1, w=4, H_ma=4, H_ca=1
A3. Pruning MA heads in lower decoder layers, D_lm=2, w=4, H_ma=4, H_ca=1
A4. Pruning MA heads in lower decoder layers, D_lm=3, w=4, H_ma=4, H_ca=1
A5. Pruning MA heads in lower decoder layers, D_lm=4, w=4, H_ma=4, H_ca=1
B1. HeadDrop, D_lm=0, w=4, H_ma=4, H_ca=1
B2. HeadDrop with pruning MA heads in lower decoder layers, D_lm=1, w=4, H_ma=4, H_ca=1
B3. HeadDrop with pruning MA heads in lower decoder layers, D_lm=2, w=4, H_ma=4, H_ca=1
B4. HeadDrop with pruning MA heads in lower decoder layers, D_lm=3, w=4, H_ma=4, H_ca=1
B5. HeadDrop with pruning MA heads in lower decoder layers, D_lm=4, w=4, H_ma=4, H_ca=1
Offline MMA models with head-synchronous beam search decoding (Librispeech960h), Table2
All models use HeadDrop and pruning MA heads in lower decoder layers with D_lm=3, H_ma=4.
Streaming MMA models with head-synchronous beam search decoding (Librispeech960h), Table3
All models use the E5 setting.
1.left/current (hop)/right=960/640/320 [ms]
2.left/current (hop)/right=640/1280/640 [ms]































